01
LightLoRA Representation
Compact LoRA factors reduce per-condition parameter footprint while keeping semantic adaptability.
Unified semantic-controlled video generation via per-reference-video LoRA.
Video2LoRA predicts a dedicated semantic LoRA from a reference video, making controllable video generation more flexible, compact, and zero-shot friendly.

Semantic alignment across diverse video generation conditions is hard. Explicit structural guidance can become rigid, while per-condition models are difficult to reuse. Video2LoRA treats the reference video as the semantic source and predicts compact LoRA weights that adapt a frozen diffusion backbone.
A short reference clip provides the semantic cue: motion, style, camera behavior, or visual effect.
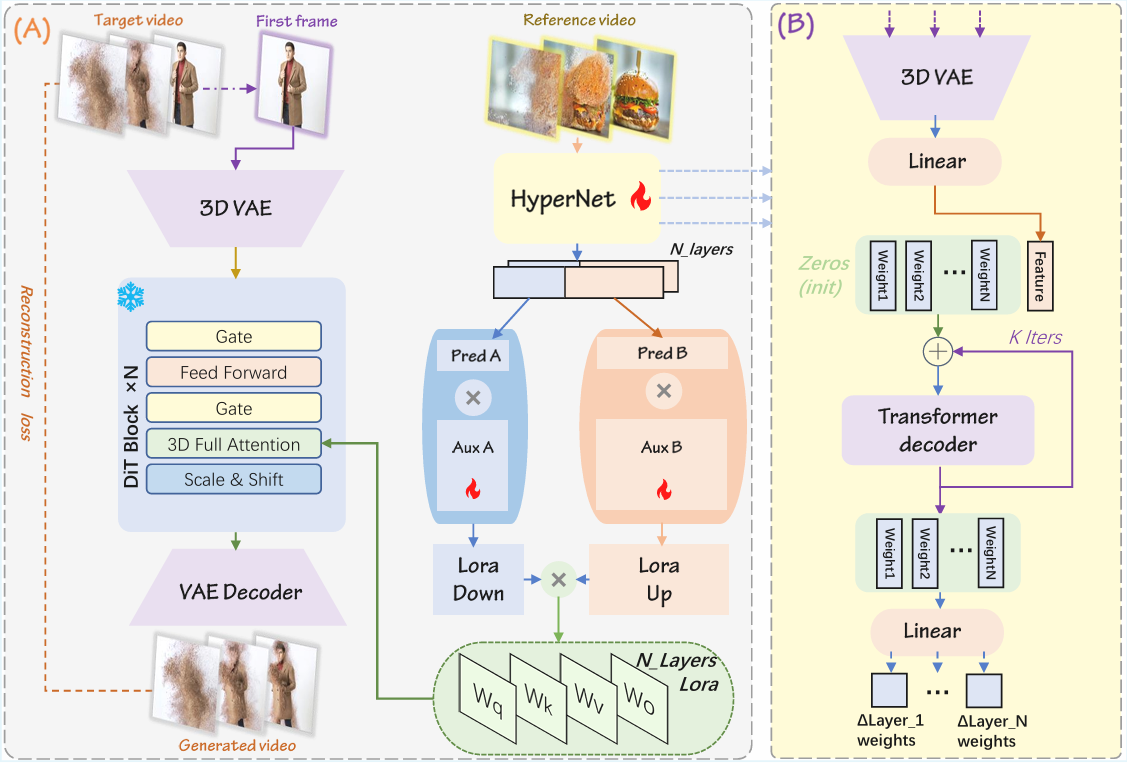
Compact LoRA factors reduce per-condition parameter footprint while keeping semantic adaptability.
A transformer-based HyperNetwork consumes reference-video features and predicts semantic-specific LoRA weights.
The predicted adapters plug into a frozen video diffusion model, avoiding per-condition fine-tuning.
@misc{wu2026video2loraunifiedsemanticcontrolledvideo,
title={Video2LoRA: Unified Semantic-Controlled Video Generation via Per-Reference-Video LoRA},
author={Wu, Zexi and Li, Baolu and Dai, Jing and Zhang, Yiming and Ma, Yue and Wang, Qinghe and Jia, Xu and Xu, Hongming},
year={2026},
eprint={2603.08210},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.08210}
}